最终成绩:第一
比赛地址:https://tech.yidianzixun.com/competition/
源码:https://github.com/LogicJake/yidianzixun-ctr-top1
典型的点击率预估问题,但是数据量非常大,总共有189766959条训练集,但只有5w条测试集。所以这题采用NN能取得比较好的效果,但由于训练集和测试集分布不一致的问题,有效抽取特征是一个难点。
赛题背景
点击率(Click-Through Rate,简称CTR)预估是推荐算法的重要模块,通常用于在用户请求推荐系统时对内容进行排序,其结果直接影响产品的核心指标和用户的消费体验。在真实环境里,用户对某条内容是否产生点击行为的原因非常复杂,既包含内容本身的信息呈现和优质程度,又包含用户的基础属性(性别、年龄等)和个体偏好,甚至与当前所处的网络环境、地理位置也息息相关。如何抽取出这些复杂的诱因并对其进行建模学习,精准预估出海量用户对不同内容的点击概率,一直是推荐算法的一个重要研究方向。
赛题内容
任务
本次大赛提供抽样用户过去一段时间内在一点资讯APP上的真实曝光和点击记录,以及所涉及用户和文章的基础属性,参赛者需要基于这些数据进行分析和建模。同时,大赛提供这批用户之后一段时间的曝光文章列表,参赛者最终提交给系统每个用户在之后曝光文章上的点击概率预估值(0-1之间的浮点数)。系统根据点击概率预估值和用户真实点击情况的差异,来评估预估任务的准确程度。 本次大赛提供的数据将隐去能代表用户身份的所有信息,对部分必要的敏感信息也进行了加密处理。
评价指标
大赛采用AUC值评估CTR预估任务的精准度,只考虑预测结果的相对顺序,消除指标分数对于阈值的依赖性。
建模
特征工程
特征工程只有两组,基于用户历史记录统计和基于全局统计。用户历史统计主要针对预测目标click和强相关的duration(消费时长)展开。这两个特征和预测目标强相关,所以基于历史信息统计,避免标签泄漏。全局信息下可以计算各组count,反应热度。
这个赛题有个明显的特点就是测试集和训练集分布不一致,训练集中每天的数据以百万记,但测试集当天的数据只有5w,明显测试集经过了采样,所以很多抽取的特征(譬如很有用的时间特征)都无法取得线上收益。第二名队伍“莲”基于上述问题,根据测试集的规模对训练集进行了分组,在组内进行特征抽取,从而做到抽取的特征分布一致,化腐朽为神奇,线上稳定上分。
模型结构
主体结构为deepfm,fm做显式二阶交叉,deep做高阶交叉。在做数据分析的时候,有些特征不同特征值的后验ctr相差较大,针对每个离散特征计算特征值对应的ctr的方差,以此来衡量后验ctr的分布差异。可以发现provice,device和city对应的特征值后验ctr分布差异明显。虽说基于对深度学习的假设,NN是可以自动学习这种分布,但是受限于数据不充分,NN无法充分学习到这种差异。因此我们将先验知识强加给NN,在现有的网络结构中显式加入“个性化学习组件”,类比FM结构让网络显式做二阶交叉。
1 | for col in tqdm([c for c in train.columns if c not in ['userid', 'docid', 'click']]): |
| 特征 | ctr方差 |
|---|---|
| province | 0.130 |
| device | 0.119 |
| city | 0.110 |
| os | 0.031 |
| age | 0.025 |
| gender | 0.032 |
| category1st | 0.036 |
| category2st | 0.053 |
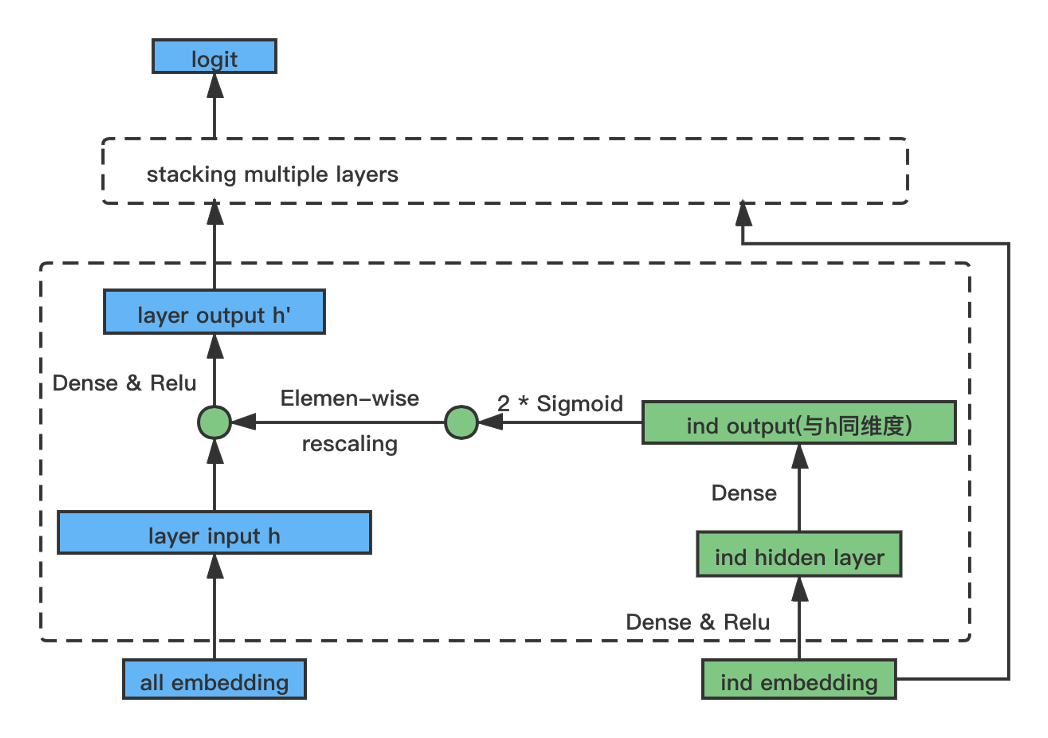
如上图所示,原始DNN的每层输入值乘上一个同维度的 scale 向量,该scale向量由一个独立的小网络得到,该小网络最后一层的激活函数是sigmoid,且✖️2,从而保证scale向量的值既能做到提升也能做到打压,拟合不同特征值巨大的分布差异。
前面做特征的时候也说到,click和duration是强相关的,duration是click之后的延伸,有点类似click和convert的关系。所以自然想到使用多任务模型结构,将duration信息迁移到click主任务。但实际尝试share bottom和mmoe均对click主任务无提升,其他队伍也尝试过ESMM。从一点资讯的实操结果看,多任务模型结构对click无提升,甚至还有损,在实际场景中使用多任务往往是出于推荐场景下的多指标综合提升。
总结
总的来说,比赛的数据很不错,充足的数据量给了NN很大的舞台,当然树模型也能做的很好。赛题主办方线下组织也很用心,在比赛之余看到了公司的文化和对员工的关怀。