最终成绩:前15(靠方案从第18向前摸了个优胜奖) / 1478
比赛地址:https://js.dclab.run/v2/cmptDetail.html?id=439
源码:https://github.com/LogicJake/2020-Xiamen-International-Bank-Financial-Cup
赛题背景
在数字金融时代,大数据、人工智能技术在银行业内的发展日新月异,业内各机构都在加速数字化转型发展。厦门国际银行作为有特色的科技领先型中小银行,多年来始终坚持发挥数字金融科技力量,践行“数字赋能”理念,持续推进智慧风控、智慧营销、智慧运营、智慧管理,运用人工智能和大数据分析技术建立智能化客户服务模式和金融智慧营销服务体系,提升营销过程的智慧化、精准化水平,在为客户提供更贴心更具可用性的金融服务。
任务
随着科技发展,银行陆续打造了线上线下、丰富多样的客户触点,来满足客户日常业务办理、渠道交易等客户需求。面对着大量的客户,银行需要更全面、准确地洞察客户需求。在实际业务开展过程中,需要发掘客户流失情况,对客户的资金变动情况预判;提前/及时针对客户进行营销,减少银行资金流失。本次竞赛提供实际业务场景中的客户行为和资产信息为建模对象,一方面希望能借此展现各参赛选手的数据挖掘实战能力,另一方面需要选手在复赛中结合建模的结果提出相应的营销解决方案,充分体现数据分析的价值。
数据介绍
数据共分为三个部分,训练集(包括 2019 年第三、第四季度,每个季度的客户信息、资产数据、行为数据、重大历史数据、存款数据)、测试集(包括 2020 年第一季度的客户信息、资产数据、行为数据、重大历史数据、存款数据),以及标签数据。建模的目标即根据训练集对模型进行训练,并对测试集进行预测。训练集和测试集中包含了有效客户和无效客户,而所给的标签中,只有有效用户的标签,同时赛题也要求只对有效用户建模,因此,本文以下的分析均为有效客户,不包含无效客户。
本方案采用的方式是将将训练集(客户信息、资产数据、行为数据、重大历史数据、存款数据)按季度合并起来,合并之后的训练集有 82899 个有效客户,而测试集有 76722 个有效客户。
详细数据字段说明
a) aum_m(Y) 代表第 Y 月的月末时点资产数据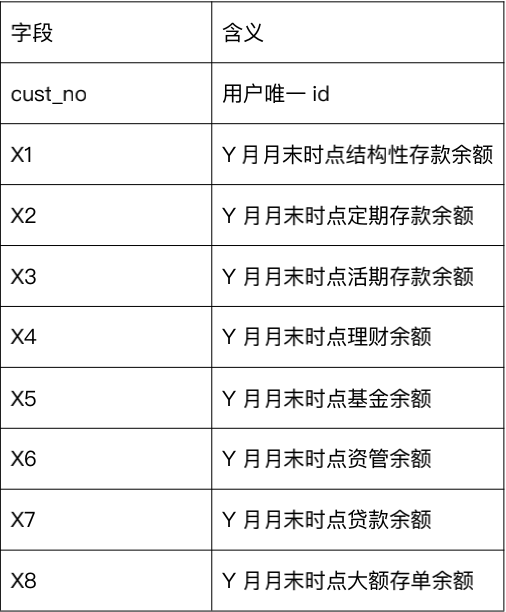
b) behavior_m(Y) 代表第Y月的行为数据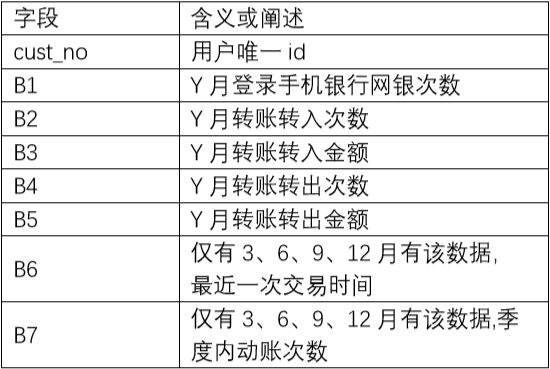
c) big_event_Q(Z) 代表第 Z 季度的客户重大历史数据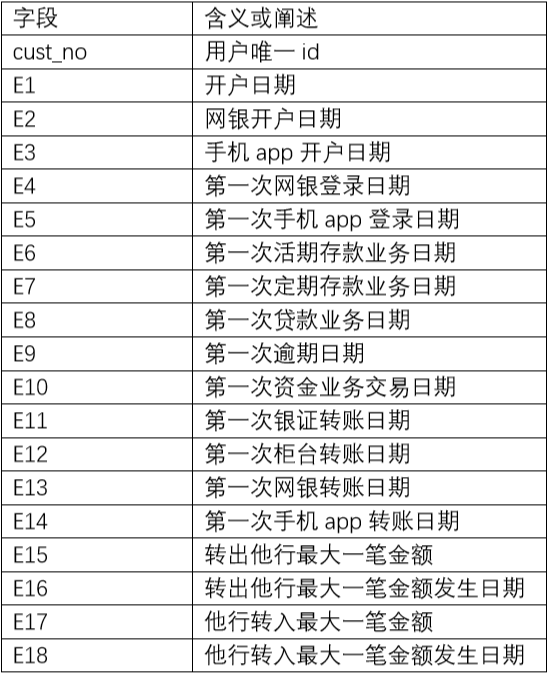
d) cunkuan_m(Y) 代表第 Y 月的存款数据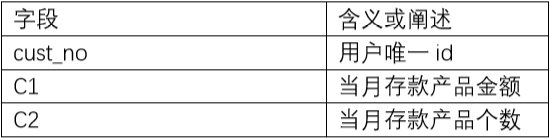
e) cust_avli _Q(Z) 代表第 Z 季度的有效客户 仅有 cust_no
f) cust_info_q(Z) 代表第 Z 季度的客户信息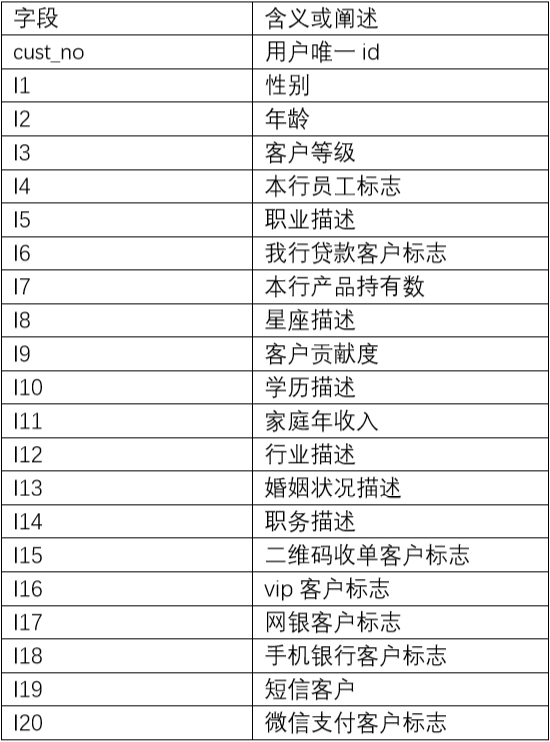
方案总结
根据工作人员的答疑,标签是根据一定业务规则和客户存款情况去给客户打标签, 反映的是客户资产的变化情况。
- -1 代表客户资产下降
- 0 代表客户资产维稳
- 1 代表客户资产上升
训练集中 63.9% 的客户属于类别 1 (资产上升);20.8% 属于类别 2 (资产维稳);15.3% 属于类别 -1 (资产下降)。
特征工程
行为数据相关特征
在行为数据中有一列特征为最近一次交易时间B6,用当季度最后一天的日期减去B6可以得到客户没有交易的天数(用B6_gap表示),以此来衡量用户的沉寂时间。该特征在线下能提升4个k,但线上却起到了反作用。探查数据后发现,存在最近一次交易日期并不在该季度的日期范围之内的现象,也就是说很多客户在这一个季度内都没用交易过。这些用户的沉寂时间过长,因此在多个季度的数据中,最后一次交易时间都是同一个很久远的日期,所以需要进行截断,将最近一次交易日期截断在本季度所属日期范围内,防止同一个用户出现越后面的季度B6_gap越大的现象。重新处理后该特征线上能提升4个k。
对其他行为数据进行了交叉处理,构造了转入转出金额之差、之比,平均每次转入金额和平均每次转出金额。
行为数据是按月给出的,需要聚合为以季度为单位的特征。对原始的行为特征和衍生的交叉特征,对季度内的月数据进行mean,std,max,min,diff,last统计。
1 | for f in tqdm(['B1', 'B2', 'B3', 'B4', 'B5', 'B5_B3_minus', 'B3_B2_ratio', 'B5_B4_ratio', 'B5_B3_ratio']): |
资产数据相关特征
该表包含了月末客户的各类资产余额,很自然的可以求和得到所有资产的总和,顺便得到拥有的不同资产的类别。本季度最后一个月的月末数据可以视为本季度结束时的数据,各类资产余额除以总资产余额可以得到季度结束时各资产的配比。资产数据也是按月给出的,对资产的总和和资产类别数,进行mean,std,max,min,diff,last统计。
存款数据相关特征
不是很明白存款数据和资产数据的区别,该表给出了当月存款产品金额和存款产品个数,交叉得到平均每个存款产品的金额。按月对存款金额进行diff得到存款金额的月变化情况。同样对原始特征和衍生的交叉特征,对季度内的月数据进行mean,std,max,min,diff,last统计。
历史事件数据相关特征
该表有客户一系列的“第一次”的日期,虽然说时间特征一般是很强的,但实际并没有挖出强有力的代表特征,仅仅对这一系列日期特征交叉计算日期差。
客户基本信息相关特征
直接merge进主表就完事了,对类别特征做了count编码,探究的比较粗糙。
季度间特征
上面的特征都是在季度内做统计,我们完全可以把每个季度最后一个月的数据视为季度数据,比如季度资产余额。这样我们就可以以季度为单位计算diff,得到各类资产余额距离上个季度的变化情况,从而得到客户的资产变动情况。该类特征提升较大,线上接近3个百。
多分类预测概率权重搜索
这也是多分类任务的一个很重要的提分trick,基本思想为暴力搜索各个类别的权重,使得预测类别的概率乘以权重后,kappa指标能提升。本质上是将模型预测的类别概率分布尽量拉到真实的标签分布,该trick线上能提升大概1.5个百。
1 | def search_weight(valid_y, raw_prob, init_weight=[1.0]*class_num, step=0.001): |
总结
这个比赛前期花费的时间比较多,后期随着挖特征收益太小,线上线下不一致,担心切榜就是摸奖,所以最后一个月基本就没提交了,就和队友融合了一下就放弃了。没想到b榜分数还是挺稳定的,而且前面有很多小号退赛,混进了前20,哈哈,无力吐槽。